Data Engineering Simplified.
DataByte is a governed platform for ingestion, transformation, ML, APIs, and operations, built together from first principles instead of stitched from separate tools. An integrated platform, one architecture, one contract.
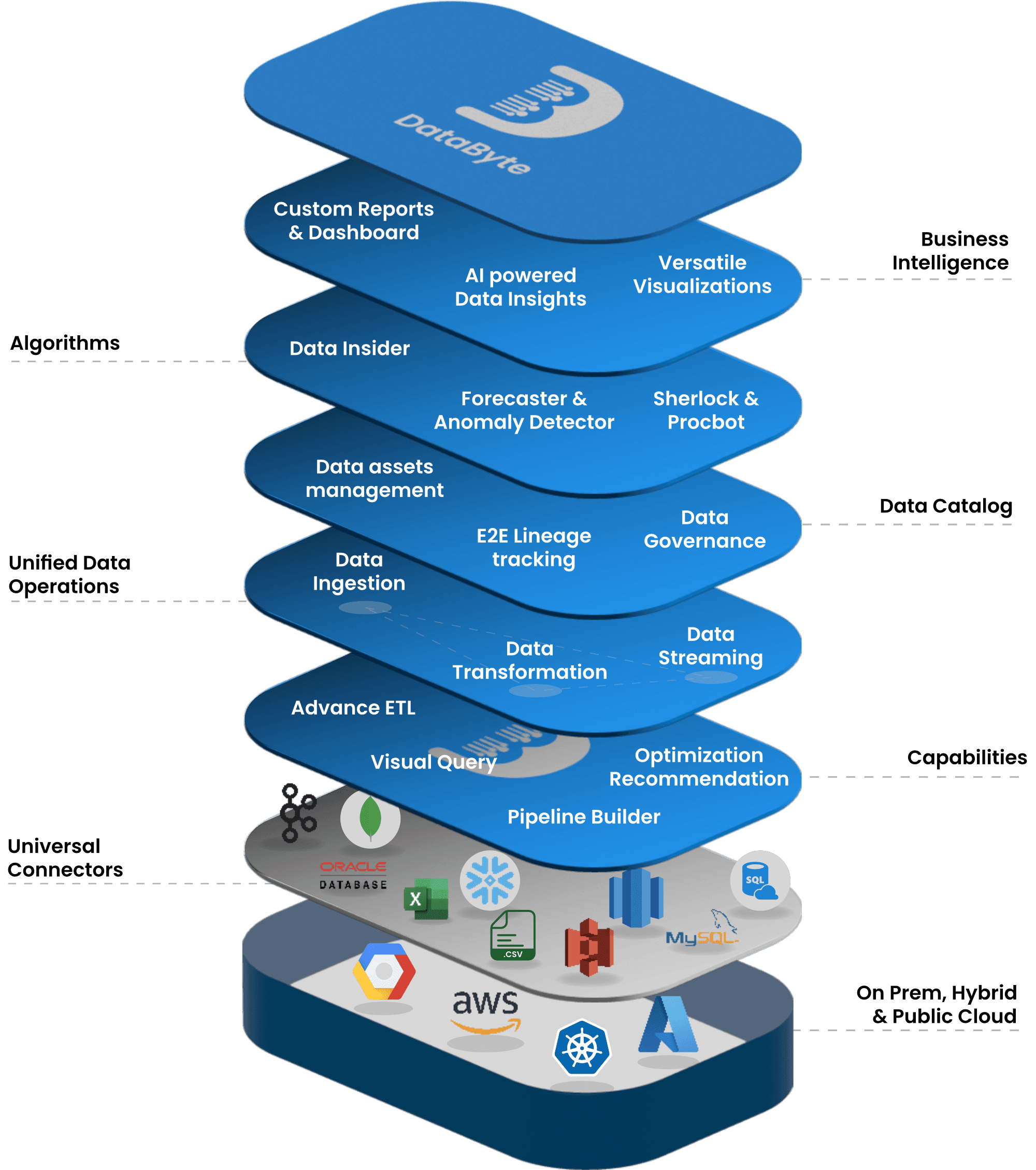
Every data stack is eight tools pretending to be one.
Ingestion tool, ETL engine, warehouse, catalog, ML platform, API gateway, BPM, BI. Each bought separately. Each governed separately. Each billed separately. The integration is left as an exercise for the reader, and that reader is your team.
- Six to nine contracts to renew, audit, and price-shop every year.
- Lineage that stops at every tool boundary; audits that become projects.
- Teams that "integrate" full-time instead of building anything for the business.
- A pilot that takes a quarter; a production rollout that takes a year.
Three decisions make the whole thing work.
We replaced 'eight perspectives' with three pillars. Architecture, Intelligence, and Operations, the decisions every data platform has to make, made once and made well.
Unified by architecture, not integration.
One data model, one governance layer, one RBAC. An integrated platform built together instead of stitched by your team.
AI that ships with the platform, not on top of it.
ML Studio, Forecaster, and Anomaly Detector cover the full ML lifecycle. A growing library of agents lets teams converse with the platform in plain English.
Governed, observed, and self-healing by default.
The SMART framework, SLA, Monitoring, Actions, Rules, Traceability, is embedded in every module. Sherlock closes the loop with autonomous remediation.
One integrated platform. One contract.
Every module is purpose-built and production-grade on its own. Together they share one data model, one catalog, one security model, and one operational surface.
Container-native pipeline engine with three modes: X→Y (batch/on-demand), Change Data Capture (log, query, and trigger-based), and Advance ETL over 2000+ connectors.
Visual no-code canvas for Spark transformation pipelines, plus a Jupyter notebook surface. Batch, streaming, and on-demand, the same engine, auto-scaled on Kubernetes.
AutoML, visual pipelines, and Jupyter in one place. One-click model deployment as versioned REST APIs. Drift detection and experiment tracking built in.
25+ time-series algorithms: ARIMA, SARIMA, Prophet, LightGBM, XGBoost, N-BEATS, and more. Scheduled runs, accuracy dashboards, and side-by-side backtests.
Near-real-time anomaly detection on SQL, Kafka, webhooks, and APIs. Continuous re-learning with separate workspaces for monitoring and model configuration.
Autonomous root-cause analysis. No-code decision trees execute on Spark, isolate failure points, and verify remediation with a closed-loop health check.
No-code workflow automation. Event or schedule-driven; conditional logic, action blocks, and first-class integration with external systems.
Expose any SQL or NoSQL source as a versioned, secured REST API. Row and column-level security, rate limiting, auth, and auto-generated Swagger included.
Built for any data team that has outgrown the stitch.
DataByte is general-purpose by design. The same platform runs CDC, ML pipelines, API delivery, forecasting, process automation, and governance, whatever mix you need.
Batch, CDC, or streaming, all governed by the same catalog and RBAC from the moment data lands.
AutoML, drift detection, and 25+ time-series algorithms ship with the platform. One-click REST deployment.
Turn any SQL or NoSQL source into a versioned, secured REST API with rate limits and auto-generated Swagger.
Sherlock runs decision-tree RCA, ProcBot automates workflows, DataOps exposes live pipeline health.
Visual report builder with scheduled email, SFTP, or API delivery, governed end to end.
The SMART framework turns GDPR, HIPAA, and SOX reporting into a report, not a project.
Connects to the stack you already have.
Two thousand plus connectors across databases, warehouses, cloud storage, streaming, SaaS, BI, and file formats. Drag-and-drop if you want it; custom code if you need it.
See it running on your stack.
Thirty-minute walkthrough. Your data, your connectors, real pipelines. No slideware.