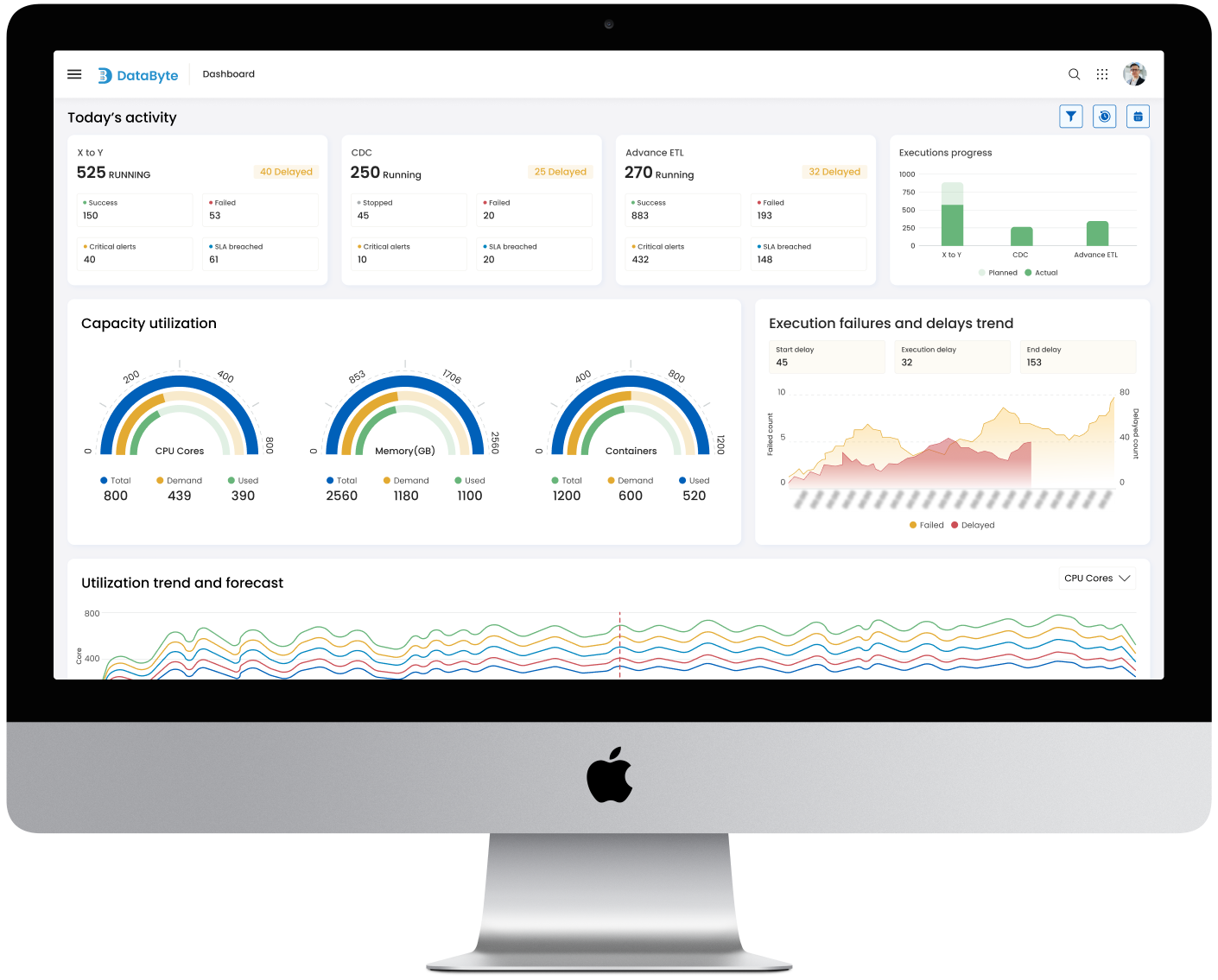
Seamless & efficient Apache spark jobs creation & orchestration
Streamline, orchestrate, monitor, and optimize your Spark jobs and pipelines effortlessly. Create and manage Spark jobs with an intuitive interface.
Kubernetes driven scalability
Orchestrate operations for optimum scalability & efficiency with kubernetes integration
Complex pipelines, code free
Build efficient spark pipelines with a drag-and-drop interface effortlessly
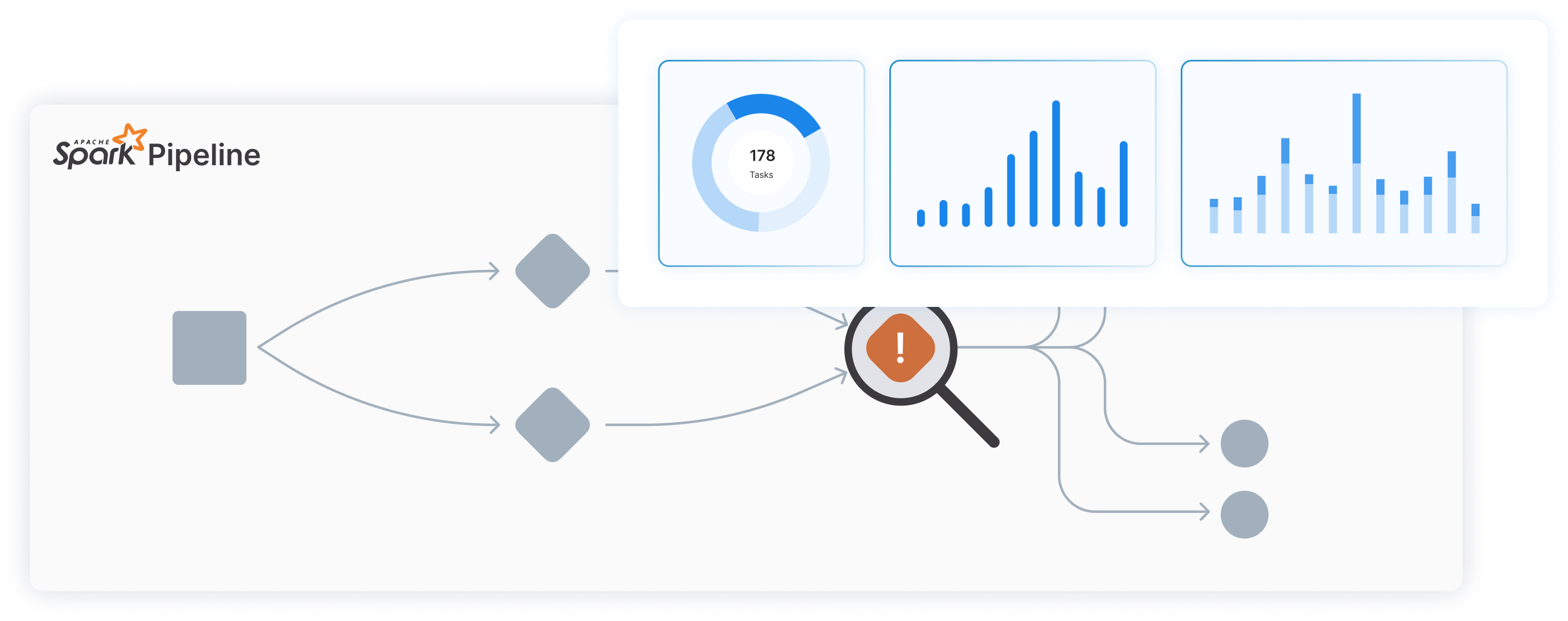
Granular insights for optimal performance
Gain valuable insights into the performance and functioning of Spark pipelines
Pipeline optimization
Reduce costs & enhance efficiency by getting optimization recommendations pipelines.
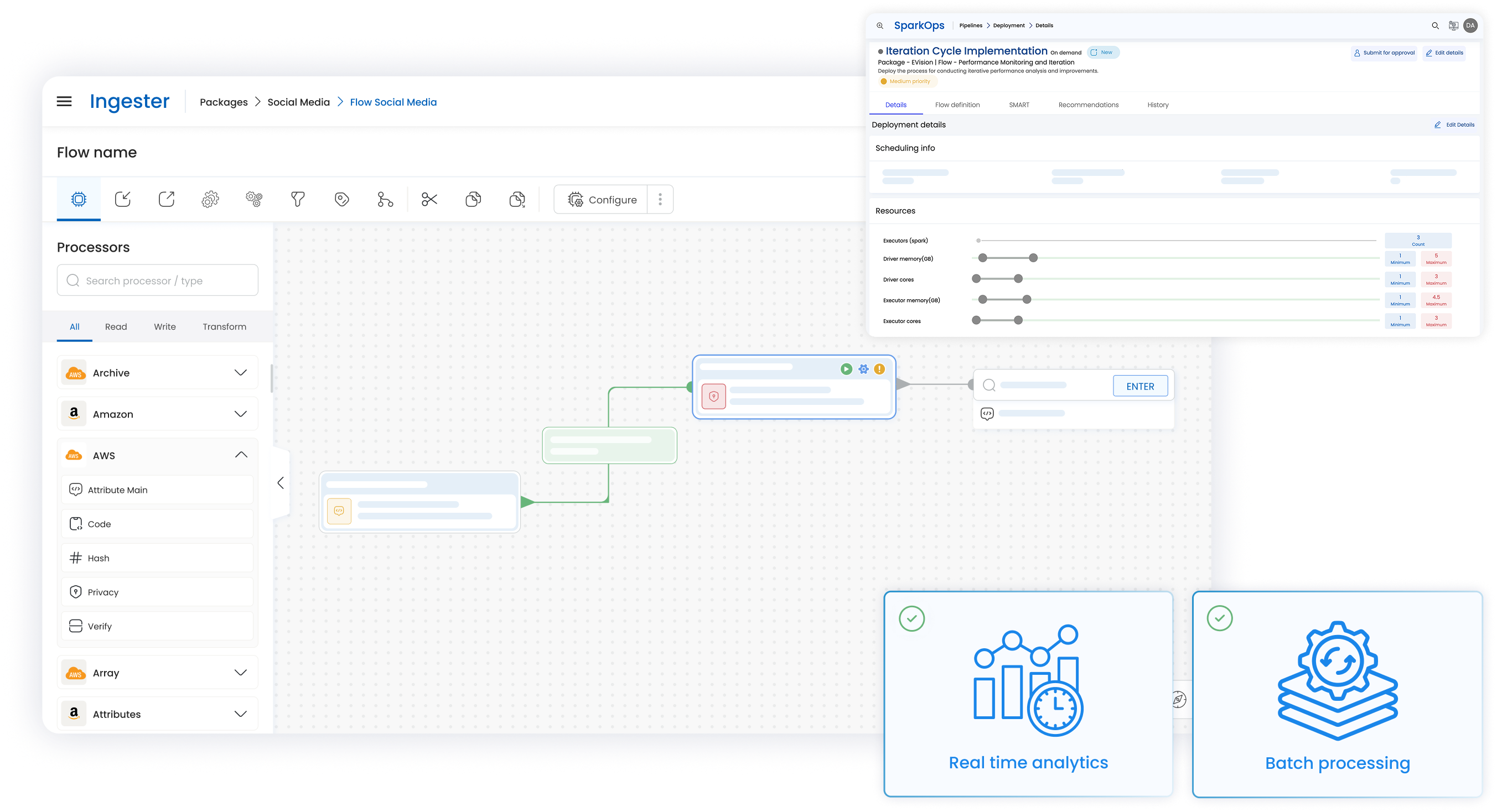
Empower teams with no-code pipeline brilliance
Say goodbye to the complexities and bottlenecks of traditional Spark pipeline creation and embrace a streamlined, user-centric approach.
With SparkOps, design intricate Spark pipelines and effortlessly deploy complex data processing workflows.
Whether it is batch processing, or real time analytics on large scale data, SparkOps' intuitive design and deployment feature ensures meeting of data processing needs swiftly and efficiently.
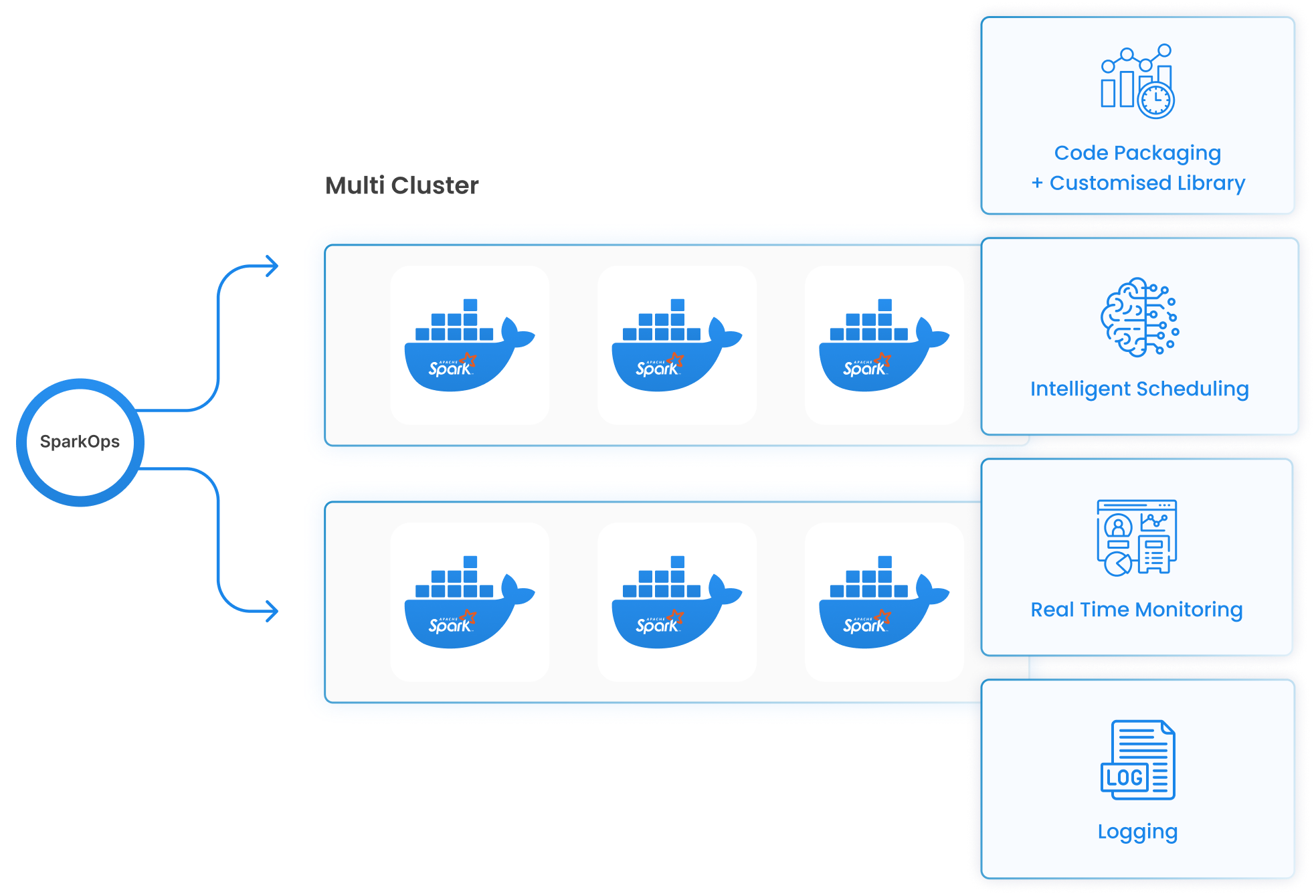
Scaling Spark with ease: Kubernetes powered efficiency
SparkOps elevates data engineering by seamlessly integrating with Kubernetes, utilizing scalability for large-scale data processing.
With this seamless integration, SparkOps empowers enterprises to harness Kubernetes' unparalleled scalability features for processing workloads.
Say goodbye to scalability constraints—SparkOps and Kubernetes together enables processing of data confidently at any scale, from terabytes to petabytes, effortlessly.
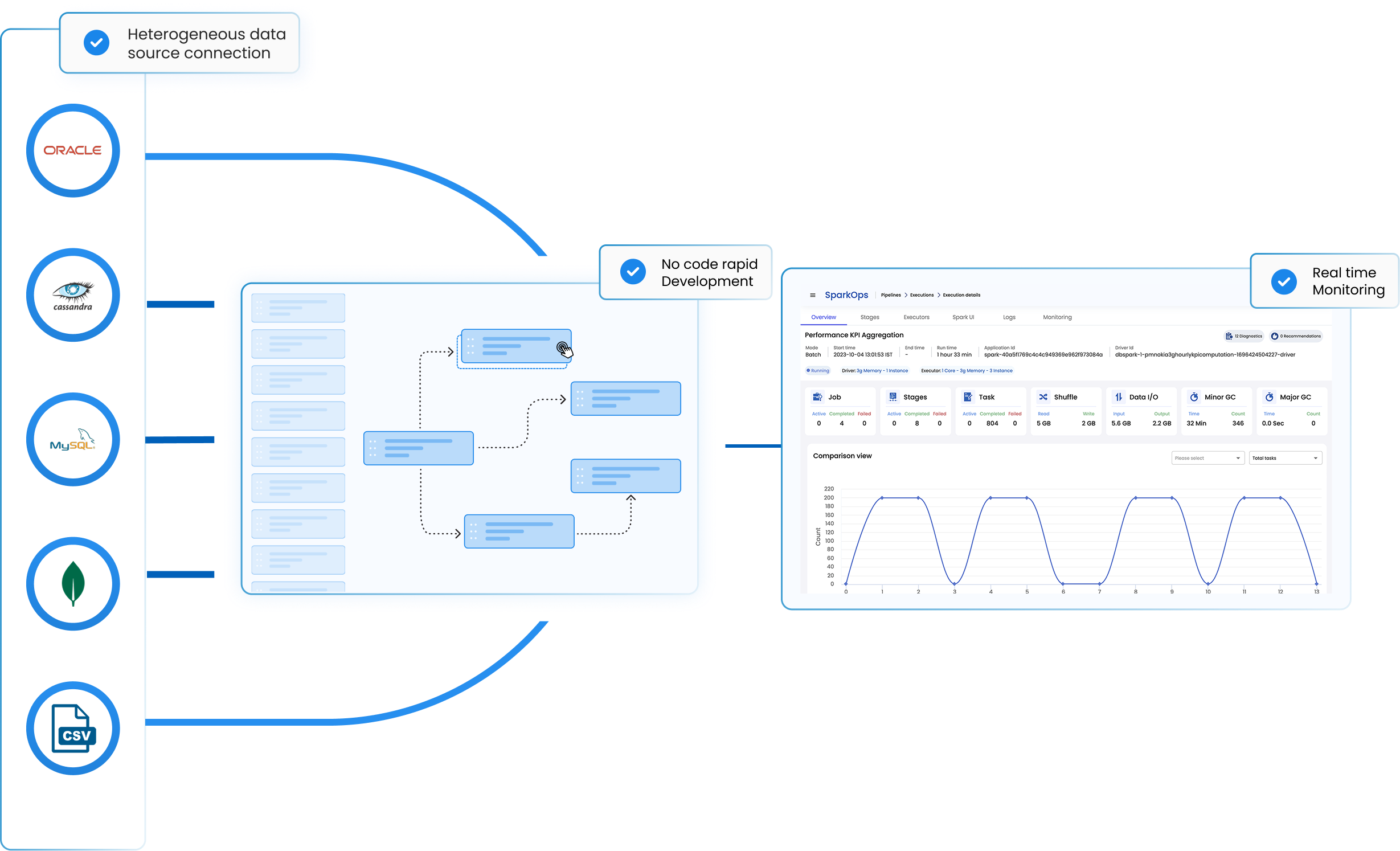
Fuelling rapid Spark job development & execution
SparkOps is engineered to streamline every aspect of Spark pipeline development.
It enables data engineers to swiftly craft intricate Spark pipelines, eliminating the need for time-consuming manual configurations and coding.
While speed is crucial, quality remains non-negotiable. It ensures that Spark pipelines meet the highest standards.
Whether adapting to changing data sources, scaling up for increased demand, or implementing real-time analytics, SparkOps is the agile companion.
360 degree visibility to ensure smooth running of data processes
SparkOps elevates the data engineering operations by providing unfiltered visibility into Apache Spark workloads.
SparkOps isn't just about monitoring; it's about ensuring the data operations run flawlessly.
Implementing SMART (SLAs, Monitoring, Actions, Rules, Traceability) framework, it provides a 360-degree view of Spark pipelines, proactively detecting and addressing potential issues before they impact data delivery, helping in maintaining data quality and reliability.
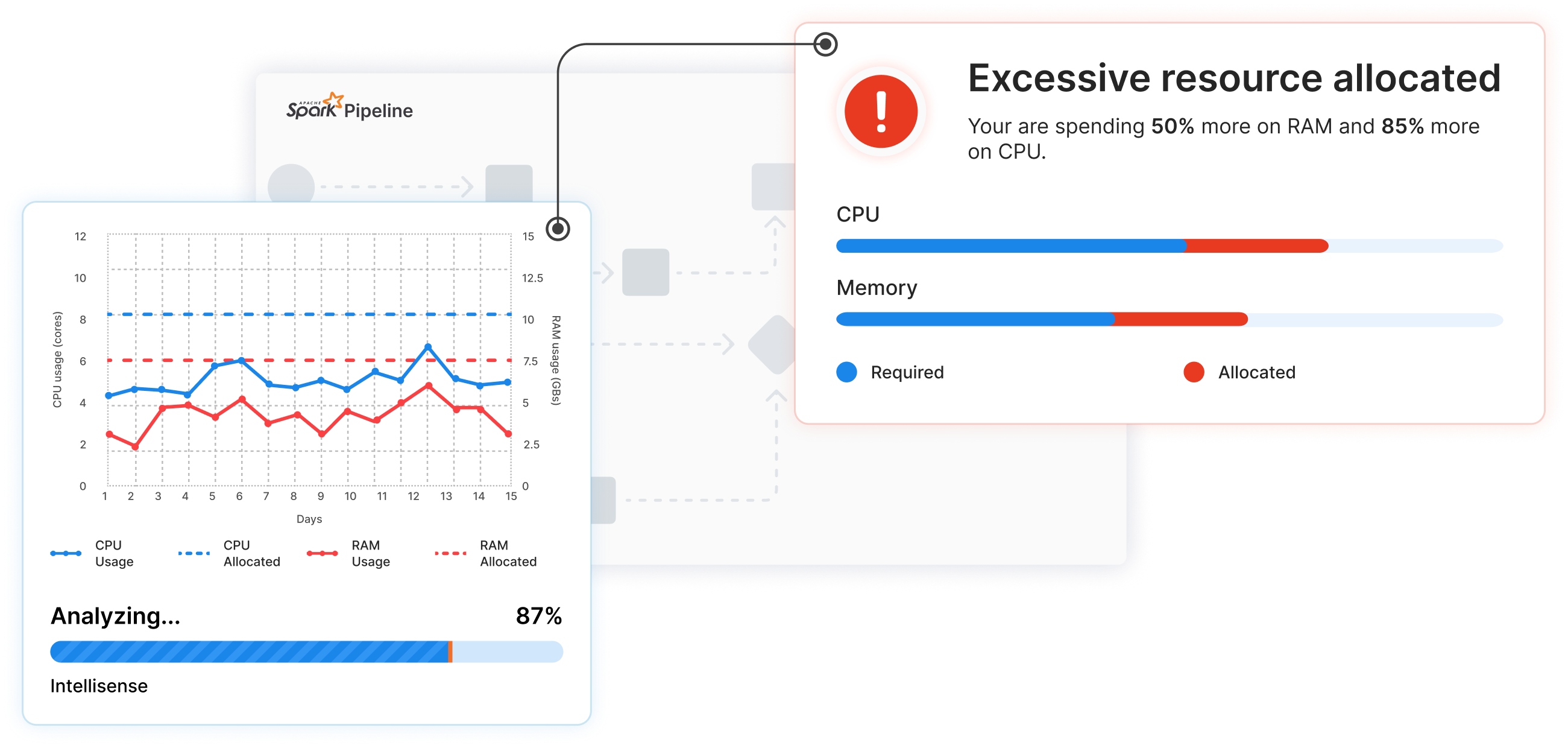
Maximize efficiency, minimize costs with intelligent recommendation engine: Intellisense
Intellisense is an intelligent companion, constantly analyzing pipeline executions to provide optimization recommendations.
By harnessing the power of data intelligence, it empowers businesses to fine-tune Spark pipelines for peak performance and resource allocation efficiency.
It offers actionable insights that allows making data-driven decisions to optimize Spark pipelines effectively.
With Intellisense, data engineering operations become smarter, more efficient, and cost-effective.